Recently, I have read an article to encourage avoid using UUIDs, but i'm still big fan for uuid due to its simplicity. Using UUIDs offers simplicity because they provide a universally unique identifier that can be generated independently without needing a centralized authority. This eliminates the need for coordination across different systems or components to ensure uniqueness, making it easier to manage identifiers in distributed or complex environments.
The most common use case is as database keys. The fact that UUIDs can be used to create unique, reasonably short values in distributed systems without requiring synchronization makes them a good alternative.
There are many versions of UUID, Here is an example UUIDv4:
9246533e-df5d-46e3-b345-f56572733f19
136f0e8c-f5b8-452e-b998-4017069b3c5a
66bb0646-b9eb-417c-acaa-cc03d8085730Each UUID has the digit 4 in the same position
Higher Storage Problem, Case: UUID as a primary key
Let's compare the storage needed for 1 million records using different primary key types:
UID as a String:
- Each UUID requires 36 bytes.
- For 1 million records:
1,000,000 * 36 bytes = 36,000,000 bytes (36 MB)
32-bit Incrementing Integer (INT):
- Each INT requires 4 bytes.
- For 1 million records:
1,000,000 * 4 bytes = 4,000,000 bytes (4 MB)
An individual UUID field requires 9x more storage space than an equivalent integer field. In addition to the default index created on the primary key, secondary indexes will also consume more space. This is because secondary indexes use the primary key as a pointer to the actual row, meaning they need to be stored with the index.
"Space" refers to the amount of storage required on disk (or in memory) to store data, including the data itself, indexes, and any other metadata that the database needs to manage and access the data efficiently.
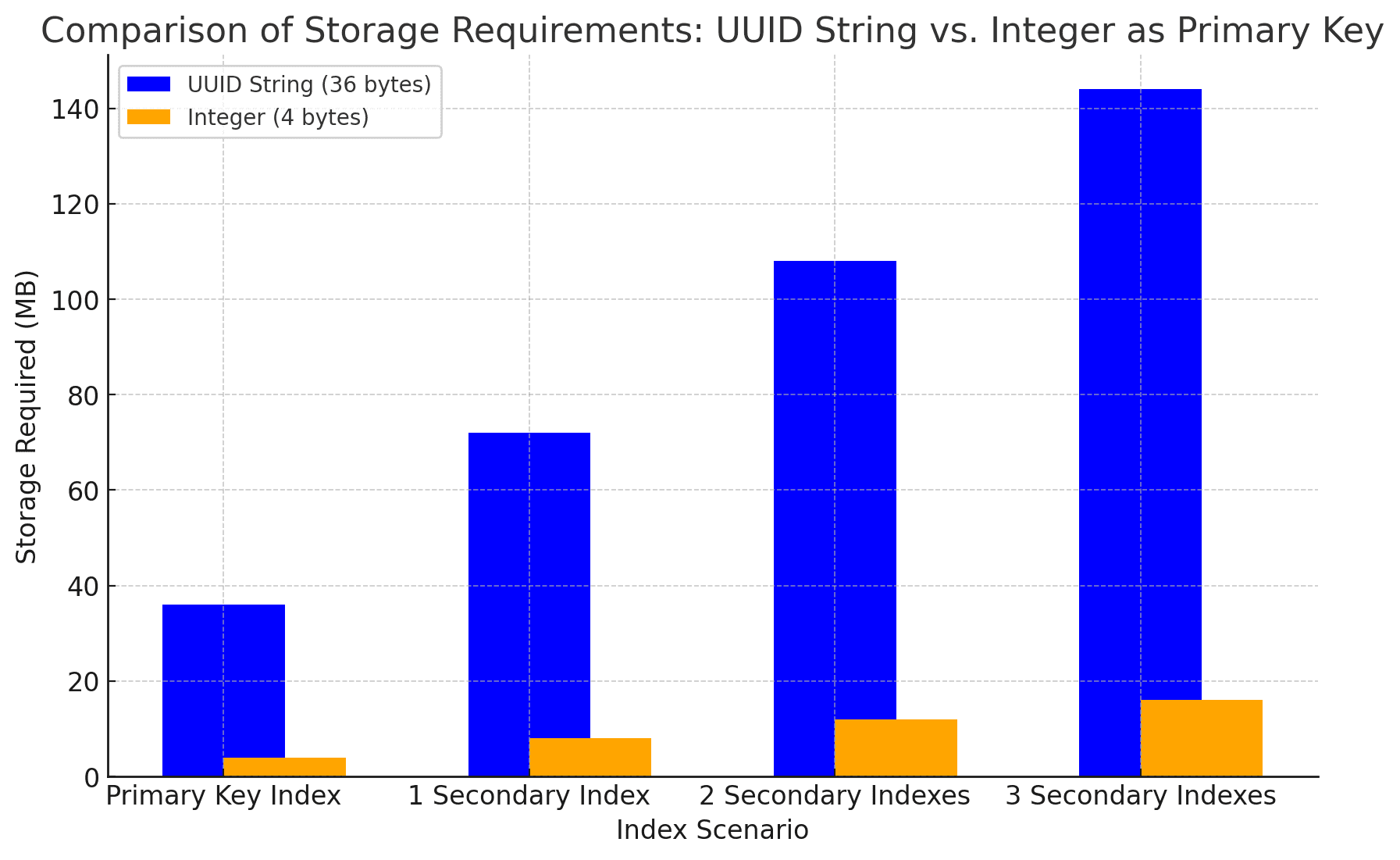
Primary Key Index:
This shows the base storage required for the primary key index alone.
1, 2, 3 Secondary Indexes:
This bars illustrate how the storage requirements increase as you add more secondary indexes, each of which must store the primary key along with the indexed data.
Example Scenario: Let's say you have a table of users:
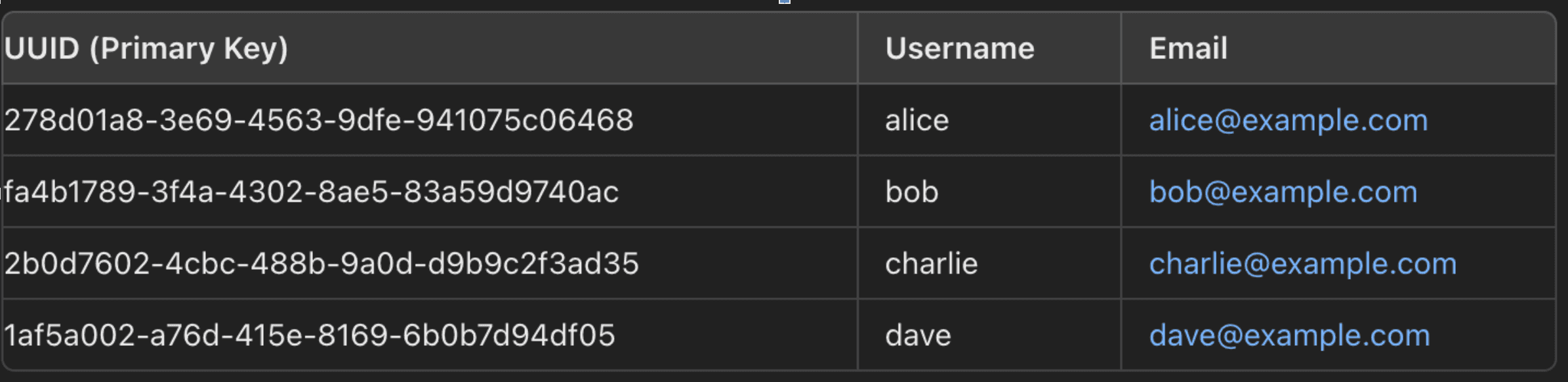
Secondary Index on Email:
- If you often search for users by their email address, you might create a secondary index on the
Emailcolumn. - This secondary index will include the
Emailvalues and theUUID(primary key) for each row. TheUUIDis stored in the index so that when a query finds theEmail, it can quickly locate the full row in the table using theUUID.
Here’s what the secondary index might look like internally:
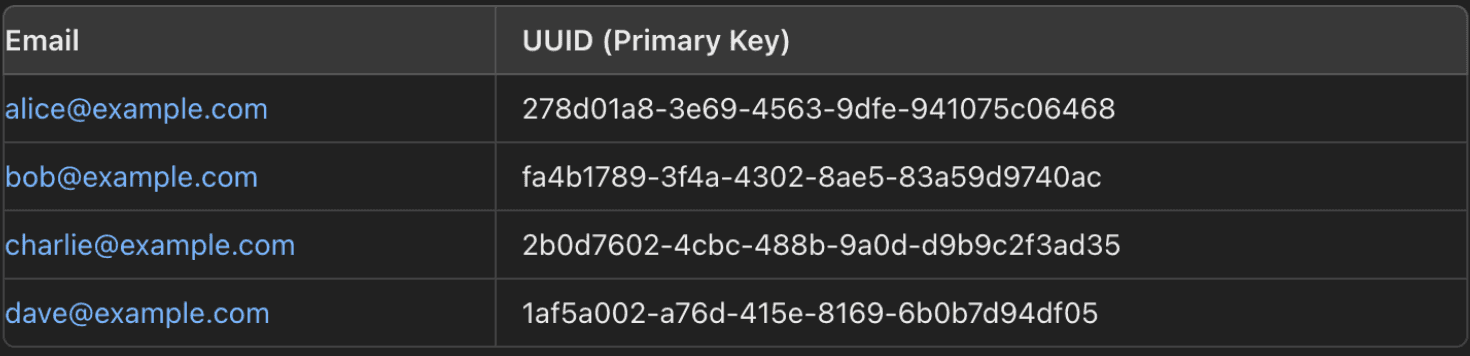
Storage Impact:
When you create this secondary index:
- The database needs to store each
Emailand also store theUUIDassociated with thatEmail. - If the
UUIDis a string (36 bytes), this storage requirement will add up for each row indexed.
So, "1 secondary index" means you have created one additional index on a non-primary key column, which will increase the storage requirements because it also includes the primary key (UUID) as a pointer to the actual data rows.
Insertion Problem
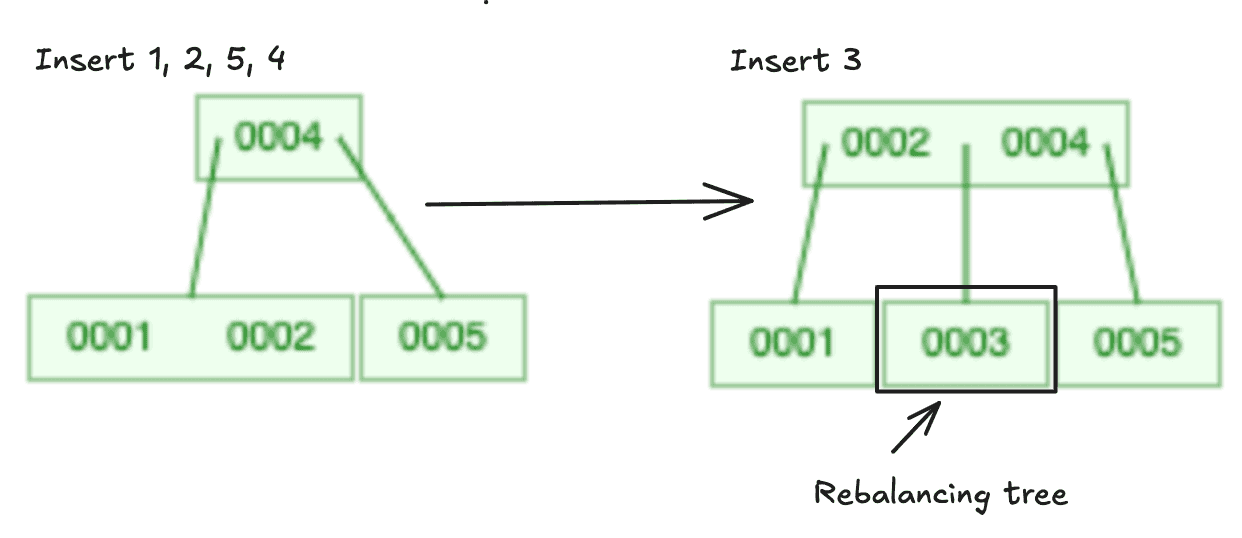
UUIDv4 have poor database index. Meaning new values created are not close to each other in the index and this require inserts to be performed at random locations
The negative performance effects of which on common structures used for this (B-tree and its variants) can be dramatic.
TL;DR: for every record insertion, the underlying B+ Tree must be rebalanced to optimize query performance. The rebalancing process becomes highly inefficient for UUIDs. This is because of the inherent randomness of UUIDs due to their inherent randomness, which complicates keeping the tree balanced.
Here’s simulation random key need to rebalancing b-tree:
Conclusion
UUIDs are a great way to ensure uniqueness between records in a table. There are a few best practices you can follow to minimize the negative side effects of doing so.
1. Avoid using uuid as a primary key:
When you create a secondary index on a UUID column, the database still needs to store the UUID in the index. However, since it's not the primary key, the index will also store a pointer to the primary key of the row. This can still lead to increased storage requirements, but it's more efficient than using UUID as the primary key.
2. Use UUIDv4 as a binary
UUIDs are typically represented as 36-character strings, but they can also be stored in their native binary format. By converting them to binary, you can store them in a BINARY(16) column, reducing the storage requirement to 16 bytes per value. Although this is still larger than a 32-bit integer, it's more efficient than storing the UUID as a CHAR(36).
For example, storing 1 million UUIDv6s as binary would require: 1,000,000 * 16 bytes = 16,000,000 bytes (16 MB)
3. Use an ordered UUID variant
Other alternatives, like UUID v6 or v7. UUIDs v6 and v7 are designed to provide better ordering properties compared to the traditional UUID v4, making them more suitable for use cases where order is important, such as database keys.
Even when they are being generated on multiple systems, time-based UUIDs such as version 6 or 7 can guarantee uniqueness while keeping values as close to sequential as possible. More Detail Explanation
Here example UUID v6:
1ef5d3ad-cda6-6000-8d7f-e6063b39e149
1ef5d3ad-cda8-6710-a8bb-b7b592388597
1ef5d3ad-cda8-6711-a19b-6e61d02602d0
1ef5d3ad-cda8-6712-8f69-4ba4b64cda63
1ef5d3ad-cda8-6713-b81a-9d0c9042b535
1ef5d3ad-cda8-6714-8062-abf1606010d4While UUIDs come with some performance trade-offs, I prefer using them in my organization due to their simplicity, global uniqueness, and security benefits. The large size and randomness of UUIDs make them difficult to guess, adding a layer of security that is particularly valuable in public-facing applications.