Configuring a connection pool is a common area where developers often make mistakes. There are several principles involved in the process, some of which may seem counterintuitive to certain developers, but are crucial to understand for proper configuration.
Consider a scenario where your website, regularly handles 10,000 users making simultaneous database requests, resulting in approximately 20,000 transactions per second. How large should your connection pool be to handle this load?
The real question isn't how large the pool should be, but how small it can effectively be!
The answer is you don’t need 10000 database connections to serve 10000 user concurrent!
“Less is More"
One connection equals one thread, with each thread managing its own connection to the database.
A computer with one CPU core can handle multiple threads or processes, which might give the appearance of running them "simultaneously.". However, because there is only one core, the CPU can physically execute only one thread at a time.
To manage multiple threads, the operating system (OS) uses a mechanism called time-slicing. Time-slicing works by rapidly switching between threads, giving each thread a small "slice" of the CPU's time. This switching happens so fast that it gives the illusion of simultaneous execution, but in reality, the CPU is handling one thread after another in quick succession.
2 Processes running simultaneously is always SLOWER than one running after the other.
Sequential vs. "Simultaneous" Execution (Time-Slicing)
If you have two tasks (A and B), running them sequentially (one after the other) on a single core is faster than running them "simultaneously" through time-slicing.
Time-slicing introduces context-switching overhead, where the OS has to pause a thread, save its state, load another thread’s state, and resume execution. This switching adds overhead, slowing down execution compared to running A and B sequentially.
This explains why, on a single core, trying to run many threads "simultaneously" will often lead to slower execution than just handling them one by one.
I/O Wait occurs when a thread or process is waiting for input/output operations (such as reading from a disk, network, or another device) to complete. During this waiting period, the CPU cannot make progress on that specific task because the task is dependent on data from external devices, which are much slower than the CPU.
Rule of thumbs
The size of your connection pool in this scenario depends on several factors, such as your database's capacity, application design, and the actual workload (e.g., query complexity and transaction duration).
A connection pool doesn't need to match the number of concurrent users. Many requests can be handled asynchronously, with threads waiting for a connection to be available in the pool.
If transactions are short and fast (e.g., simple reads or writes), the pool can be smaller since connections are released quickly for reuse. If transactions are long-running, you may need a larger pool.
Estimate the pool size as roughly 1.5x to 2x the number of CPU cores available on your database server. This allows for efficient handling of database requests without overwhelming the server with too many open connections.
Connection Pool Size=(Number of Cores×2)+(additional buffer for bursts)
If your database server has 32 CPU cores, a reasonable connection pool size might be: 32×2=64 connections, with a buffer of 10-20 for burst traffic. So, you might start with a pool size of 64-80 connections and monitor performance.
Experimentation
Let's conduct a small experiment. I'll run the MySQL service on macOS and perform a benchmark by executing queries to the database with 10, 20, 30, up to 100 connections. Then, we can compare the results.
I'm using sysbench to perfrom load testing.
Data Preps
oltp_read_write: This specifies the benchmark mode SysBench is running. In this case, it's an OLTP read-write test, which simulates typical read and write operations found in transactional applications.
sysbench --db-driver=mysql --mysql-user=root --mysql-password=welcome1 \
--mysql-db=sysbench_test --table-size=1000000 --tables=1 oltp_read_write prepareScript Load With # Connections
sysbench --db-driver=mysql --mysql-user=root --mysql-password=welcome1 \
--mysql-db=sysbench_test --tables=1 --table-size=1000000 --threads=100 \
--time=60 --report-interval=10 oltp_read_write run
For each test, update the --threads value to 10, 20, 30, and so on up to 100, and repeat the test. This will help assess how the system performs with increasing levels of concurrency.
Result "Latency vs Number of Connections"
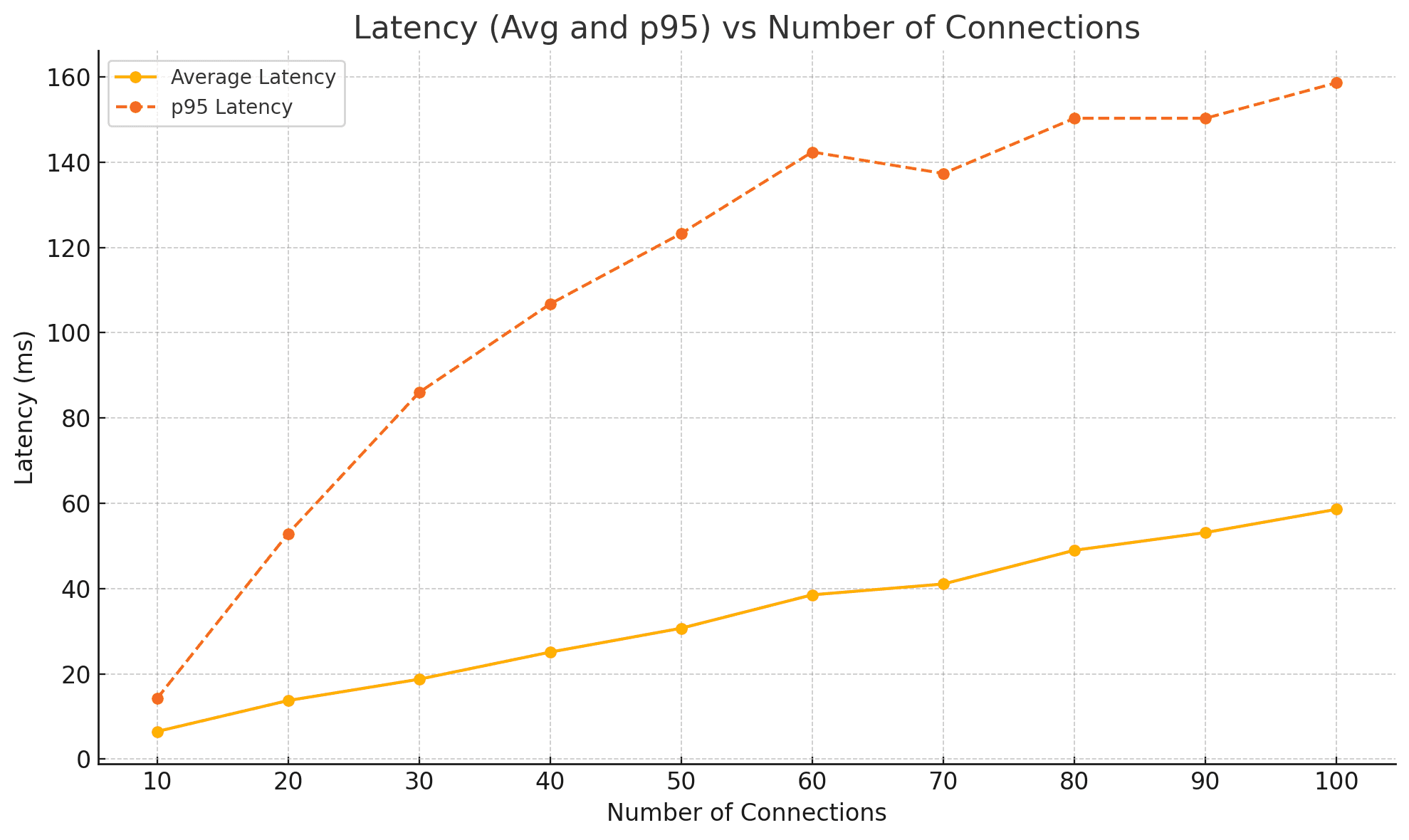
An increase in the number of connections leads to higher latency.
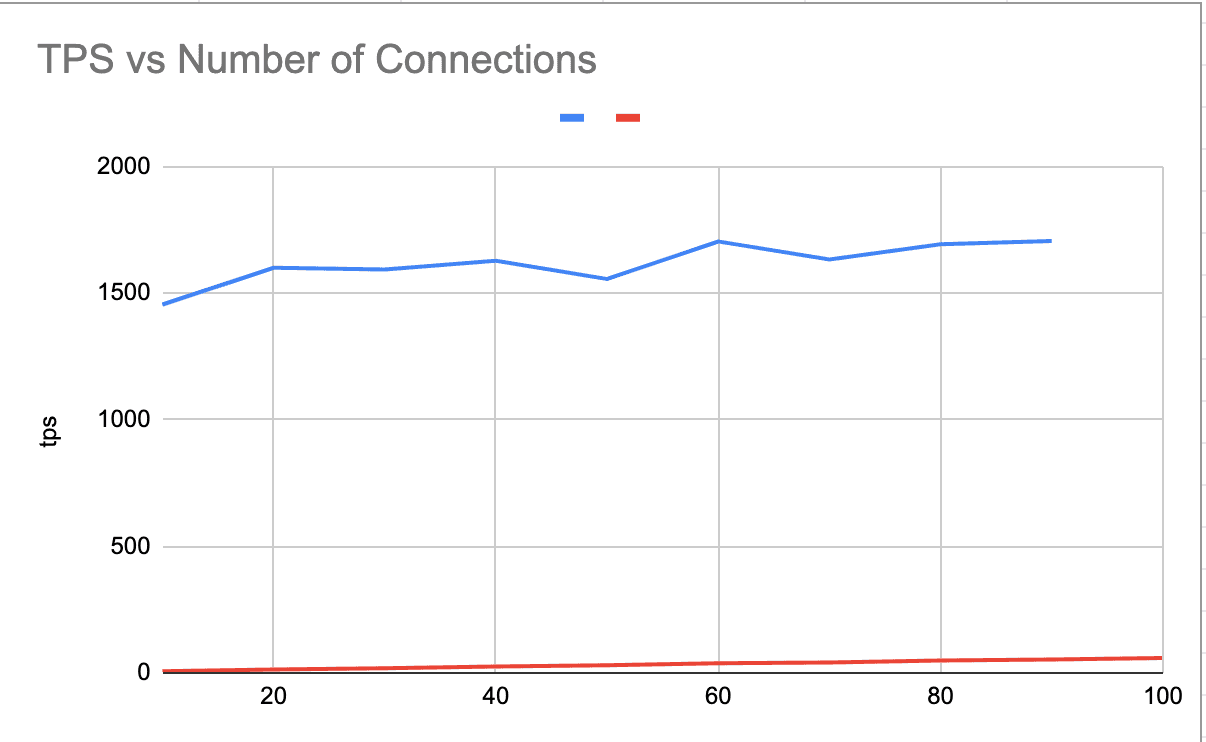
As the number of connections increases, both average and p95 latencies rise, showing that handling more connections leads to slower response times due to the overhead of managing many threads. But TPS (Transaction per second) only slightly increase.
Another important factor, besides TPS or latency, is resource utilization (CPU). A small number of connections will increase I/O wait but result in lower CPU utilization. Finding the balance between TPS and resource utilization is crucial; typically, maintaining CPU load around 60% allows for a 20-30% buffer to handle burst requests.
Caveat
Several other factors come into play when considering database performance. The primary bottlenecks typically fall into three categories: CPU, Disk, and Network. In this blog, I will focus specifically on "Basic Setup Connection Pooling."
Additionally, managing long-running transactions is often one of the most challenging aspects of tuning a connection pool.